2023 iThome 鐵人賽
分享至
其中它有一個 Dataset 專區,提供許多已經被整理好的資料提供大家下載。
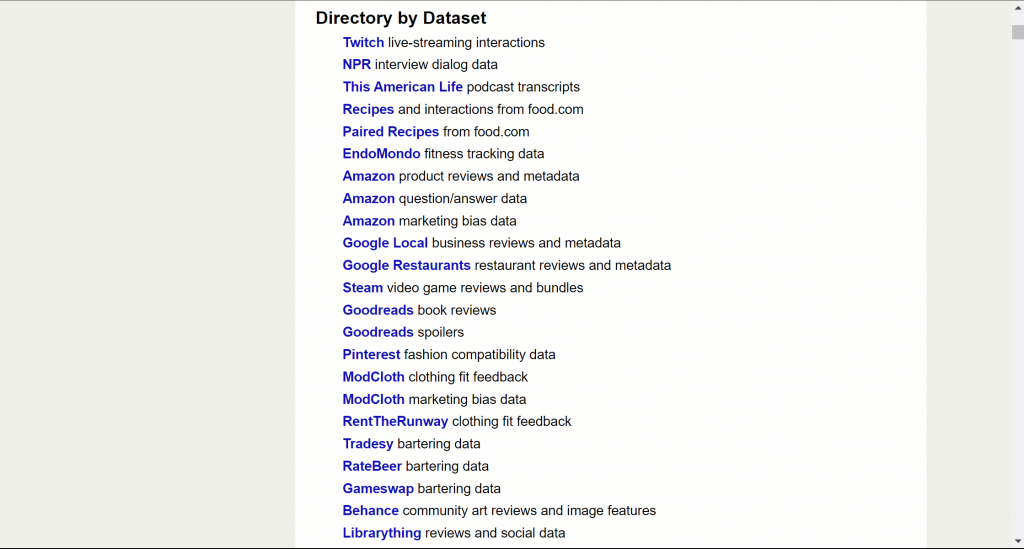
這些數據集包含了各種特徵,如用戶和物品的互動、星級評分、時間戳、產品評論、社交網絡數據、物品之間的關係(例如共同購買和兼容性)、產品圖片、價格、品牌和類別信息、GPS數據、心率序列等等。
IT邦幫忙




 iThome鐵人賽
iThome鐵人賽